Setting up various deep learning based AI models for simulating musical tasks requiring creativity.
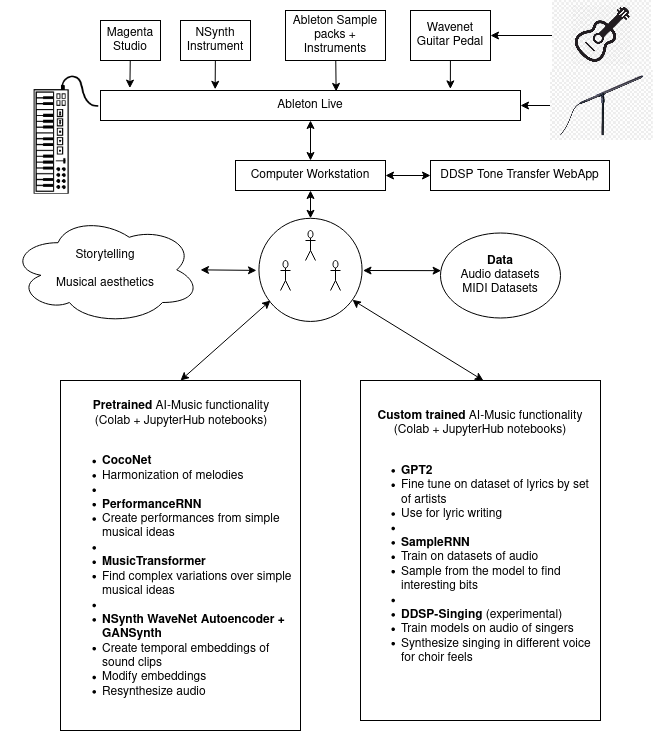
In the part 2 of this journey, we decided the kinds of data and datasets that are important to our setup. Once we are able to assemble such datasets, we need generative models which learn representations of data. These models must be able to digest a musical dataset to learn and store meaningful patterns within its network weights. After the learning process, they must generate data which maintains the semantic and syntatic integrity of the training data used. This is very important when using models to generate music, because malformed outputs just sound really bad. The model must learn in such a way that its knowledge generalizes across the training dataset. This would mean that outputs generated by the model after learning must be similar to the training data used.
In our case, we deal with three types of data:
After some discussion during our team meetings, we realized that the types models we require depend on the types of musical tasks we want to accomplish. So we first mapped out a basic outline of our creative process, in order to understand what tools will be needed and how they will be setup.
So the musical creative process was broken down into three stages:
- Ideation, Composition and Giving it sound.
Ideation
- Here, our main goal is to build the story, about which the music that we generate is going to be.
- The medium for stories is usually written language. In our case, we want a model which can generate pieces of text with a fairly coherent storyline in the English language. It must be able to create a story from nothing and also must be able of continuing a story. The GPT-2 model fits perfectly with this description. Also, since GPT-2 is a pretrained model, it saves us a lot of costly compute, and allows us to fine tune very quickly!
- But music also has its own language. To create musical notes using AI models, we use an electronic standard called MIDI. This standard is fairly portable across hardware and software, and helps us interact with the AI models in terms of composition of musical ideas within our DAW.
- To create musical ideas, we use MusicRNN and MusicVAE models by Google Magenta Project. They have models that work with different types of representations of MIDI data, and they all achieve some particular musical task. They also created Magenta studio, an M4L device which integrates various models into apps useable within Ableton Live.
Composition
- In this part, we finalize a basic outline to our story and start creating a composition for the same
- Here we put together various melodic and percussive ideas from Magenta studio (Melody and Drums). Magenta studio has five apps - Generate, Continue, Interpolate, Drumify and Groove. Each of these apps uses a DL model to achieve a specific musical task, and they all work with MIDI data.
- Using these apps, we built ourselves various workflows to create musical ideas. We always start with Generate, to create fresh ideas. If we like a musical idea, we use Continue to ‘continue’ the idea. If we aren’t happy with the continuation, we interpolate between the input sequence and a continuation. We do the same for melody and drums. In the case of drums and percussion, we have the extra step of adding dynamics to the beats. The catch here is that none of these tools understand much music theory - so usually their outputs don’t sound so great. But if we simply force the outputs of the models to be in a certain key or scale, we save ourselves a lot of time in terms of evaluating outputs.
- To explore more, we tried using PerformanceRNN and MusicTransformer to suprise us with new ideas. And it did! The generated outputs were well formed pieces, especially with MusicTransformer. Lots of inspiration to find here!
- All our generated outputs in this stage are in MIDI.
Giving it sound
- The last step in this process is to give sound to the musical composition created with the AI tools. This is where we sit down and create the real song. Until now, we were only collecting and trying various combinations of musical ideas.
- We decide which genre of music we want to suit, what instruments are needed, and how to use previously generated outputs or create news ones.
- We also try to give life to our story through some basic sound effects and musical cues.
- For this, we put things together in Ableton Live and play with our audio AI models - DDSP, SampleRNN and NSynth.
- DDSP is used for resynthesizing singing in a different voice. SampleRNN is used for recreating sound environments and NSynth is used for playing around with sounds in its encoding space.
- We use these to give an AI feel to the song.
One important thing to note is the medium of interaction with these models. Generative models are not so nice to interact with in a musical context unless we have some interface which abstracts away the mathematical complexity. In our case, we try to ensure that each AI model has an interface which is either a M4L device / VST accessible within Ableton Live, or a Jupyter / Colab notebook within an accessible GPU environment. We interact with MIDI language models within Ableton Live. We interact with some MIDI models (PerformanceRNN, MusicTransformer, CocoNet), audio models and text models in the browser or terminal. Simpler models are able to have more useable interfaces. Complicated models usually have less interactive interfaces. We are always trying to reach the right balance between all these tools by trying to optimize our workflows.
So this is a brief description about the various deep learning models we plan to use and how we plan to use them.